
[번역] Flask에서 백그라운드 작업 처리하기
Flask 에서 백그라운드 작업을 병렬적으로 처리하는 방법에 대해 알아보았습니다.

![[번역] Flask에서 백그라운드 작업 처리하기](/content/images/size/w2000/2020/05/img1-white-1.png)
Python Flask 프레임워크를 이용해 개발을 진행하던 도중, 네트워크 상에서 크롤링을 해야 하는 상황을 맞이하게 되었습니다. 이를 위해 메인 쓰레드와는 별개로 백그라운드 작업을 처리할 수 있는 방법을 찾다가 Background jobs with Flask라는 글을 발견하였습니다. 이 문서를 읽으면서 스스로 정리하면서, 이후 글을 보시는 모든 분들이 지식을 더 쉽게 습득하실 수 있게끔 번역을 진행하기로 하였습니다.
번역을 하기 위해 원문의 라이센스를 확인해보았는데, 어디에도 라이센스를 명시를 해주지 않으셔서 직접 메일을 보내 허락을 받았습니다. 그러나 추후 문제가 되는 부분이 발견된다면 일부 수정 또는 비공개 처리될 수 있습니다.
이번 번역 글에는 의역이 다수 포함될 수 있습니다.
Special Thanks
오탈자, 오역에 대해 검수를 해주신 분들입니다. 정말 감사합니다.
개요
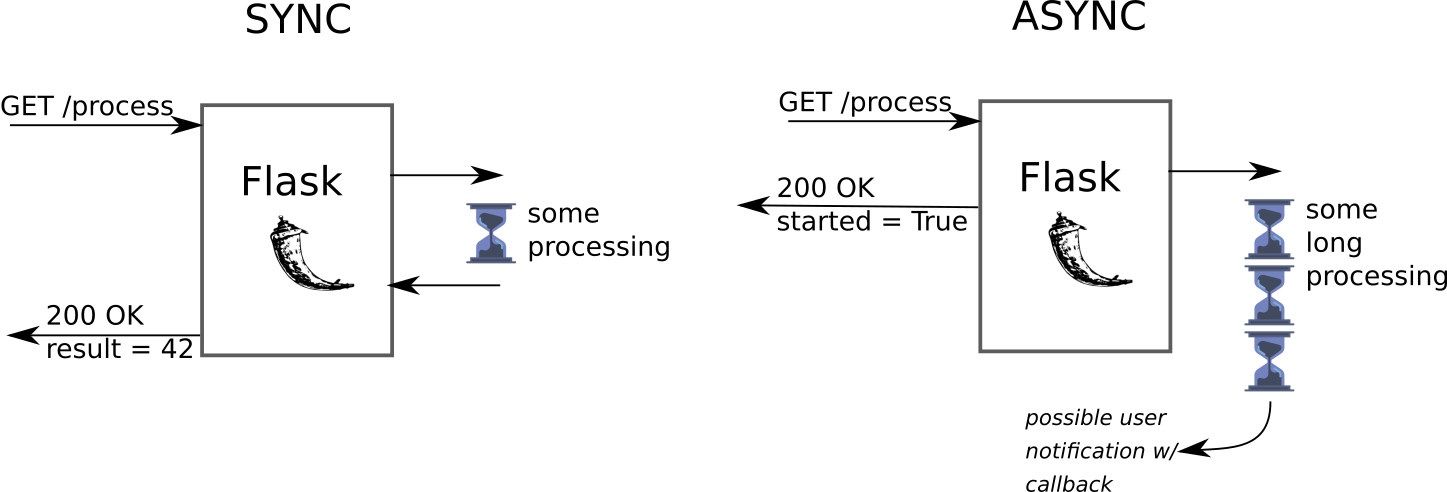
Flask 가 요청을 받았을 때 해당 요청을 처리하는 생명 주기는 다음을 따릅니다.
- Flask 가 새로운 요청을 받습니다.
- 인자 값들을 파싱합니다.
- 요청을 처리합니다.
- 요청에 대한 결과를 반환합니다.
사용자의 요청에 대해 즉시적인 처리가 가능하다면 이러한 생명 주기를 거쳐 처리가 되어도 문제가 되지 않습니다.
그러나 사용자의 요청을 짧은 시간 내에 처리하기 힘든 경우가 있습니다.
예를 들면 이러한 경우들입니다.
- 이메일을 보내야 하는 경우
- 업로드 된 이미지의 썸네일을 만드는 경우
이러한 경우에는 사용자에 요청이 들어왔을 때 처리하지 않고, 백그라운드에서 비동기적으로 작업을 처리할 수 있습니다. 동시에 사용자에게는 이 작업은 즉시 처리할 수 없으니, 비동기적으로 작업을 시작하였다고 알려줍니다.
본 글에서는 위에서 소개드렸던 Flask 에서 비동기적으로 작업을 처리할 수 있는 방법에 대해서 알아보고자 합니다.
일반적인 구현 방법
비동기 작업은 보통 다음 방법으로 구현합니다.
- 플라스크에서 새로운 요청이 들어왔을 때 메세지 브로커(Redis, AWS SQS, RabbitMQ 등)에게 메세지를 전달해 작업을 예약합니다.
- Worker의 Pool에서는 브로커를 통해 메세지에 접근할 수 있습니다. (이때 Worker는 물리적으로 분리되어 있을 수 있습니다.)
- Worker 는 브로커로부터 메세지에 접근하여 작업을 실행합니다.
이러한 접근은 몇몇 장점이 있습니다. 첫번째로, 해야 할 일을 명확하게 나눌 수 있습니다. 플라스크 웹 서버는 요청을 전달하는 한 가지의 작업만 하게 됩니다. 만약 많은 연산이 필요한 작업을 받더라도, 플라스크 인스턴스는 높은 메모리/CPU 사용량을 걱정하지 않아도 되며, 계속 요청을 처리할 수 있습니다. 두번째로, 작업은 메세지 브로커에 저장됩니다. 이는 플라스크 인스턴스가 죽는다고 하더라도, Worker 과 작업 실행에는 영향을 끼치지 않습니다.
그러나 세상에 공짜는 없습니다. 이 구조는 다른 구현 방법들보다 실패할 지점이 많습니다. 브로커 기능을 제공하는 라이브러리들에 버그가 있을 수 있습니다. 또한 이것은 쥐잡는데 소 잡는 칼 쓰는 것처럼 보입니다. (오버-엔지니어링)
이 방법을 구현하는 좋은 예시들이 몇 개 있습니다 : RQ, Celery
다른 구현 방법
쓰레드
가장 기본적인 접근은 쓰레드를 통해 작업을 실행하는 것 입니다. 이 것을 위해서는 아래 옵션을 uWSGI 설정 파일에 추가해줘야 합니다.
enable-threads = true
Flask with uwsgi in production 강좌에서 사용한 소스코드를 통해 예시를 보여드리겠습니다.
다음은 app.py 파일의 소스코드입니다.
import os
import time
from flask import Flask, jsonify
from threading import Thread
from tasks import threaded_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
@app.route("/", defaults={'duration': 5})
@app.route("/<int:duration>")
def index(duration):
thread = Thread(target=threaded_task, args=(duration,))
thread.daemon = True
thread.start()
return jsonify({'thread_name': str(thread.name),
'started': True})
다음은 tasks.py 파일의 소스코드입니다.
import time
def threaded_task(duration):
for i in range(duration):
print("Working... {}/{}".format(i + 1, duration))
time.sleep(1)
다음은 실행 예제입니다.
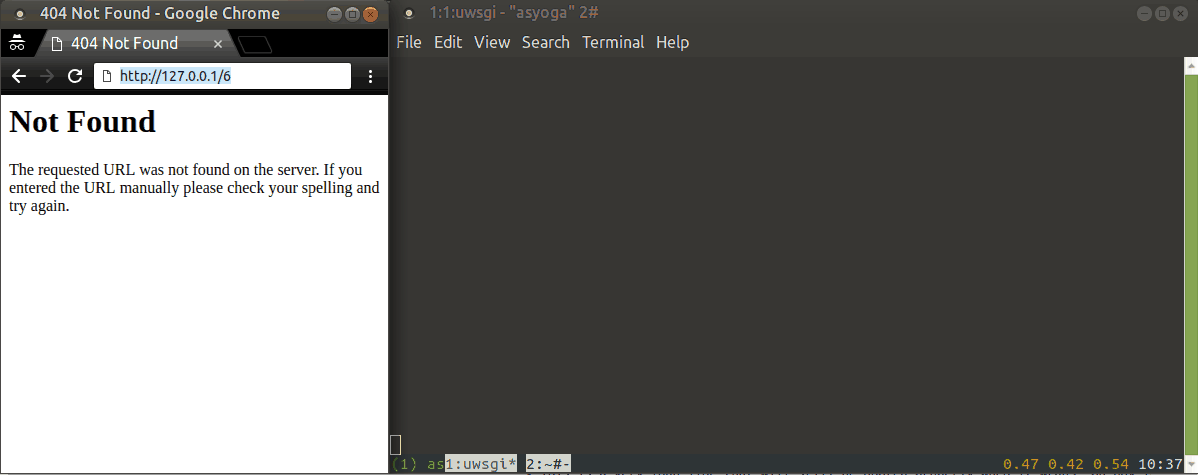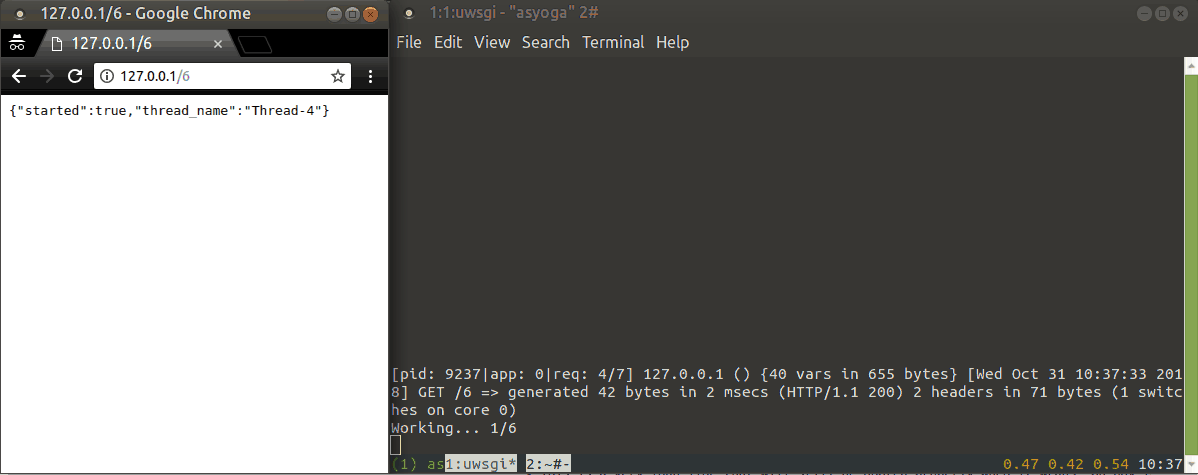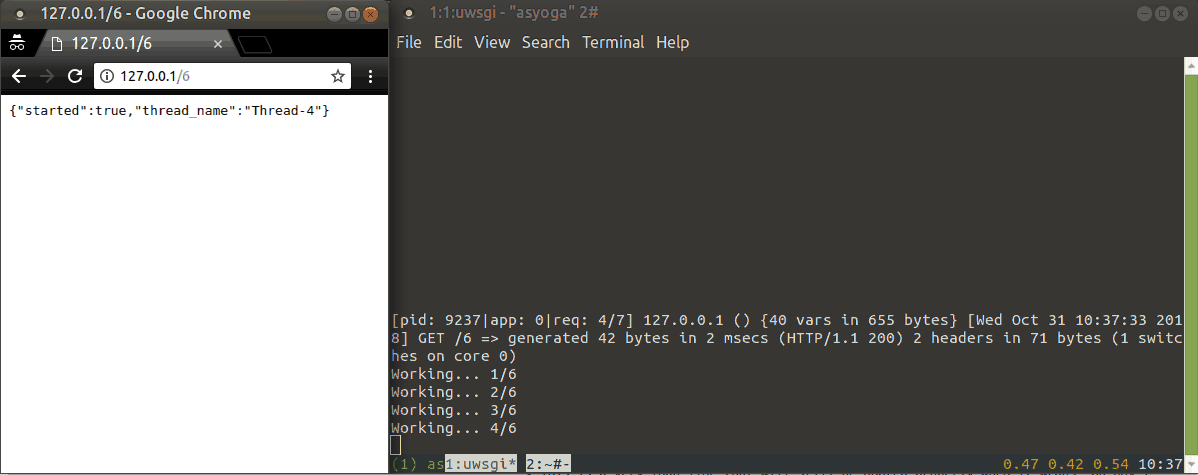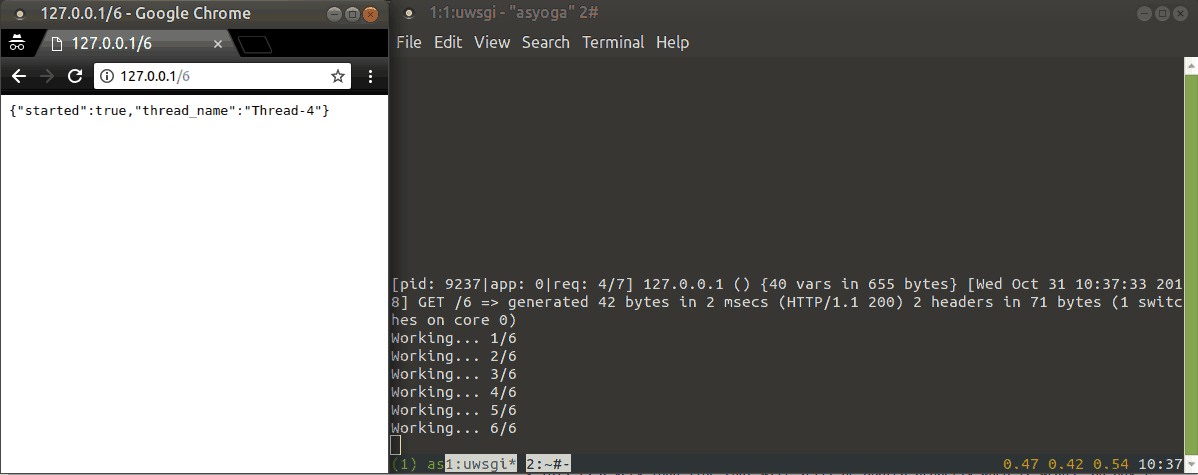
uWSGI 쓰레드
쓰레드를 만들고, 실행하는 것을 uWSGI 에게 맡길 수 있습니다. 이 방법을 사용하면 쓰레드 모듈을 직접 사용할 일이 없습니다. 이 방법을 사용하기 위해서 만들어진 thread 모듈의 데코레이터인 from uwsgidecorators import thread 를 사용하면 됩니다. (API 명세)
다음은 app.py 파일의 소스코드입니다.
import os
import time
from flask import Flask, jsonify
from threading import Thread
from tasks import uwsgi_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
@app.route("/uwsgi_thread", defaults={'duration': 5})
@app.route("/uwsgi_thread/<int:duration>")
def uwsgi_thread(duration):
uwsgi_task(duration)
return jsonify({'started': True})
다음은 tasks.py 파일의 소스코드입니다.
import time
from uwsgidecorators import thread
@thread
def uwsgi_task(duration):
for i in range(duration):
print("Working in uwsgi thread... {}/{}".format(i + 1, duration))
time.sleep(1)
다음은 실행 예제입니다.
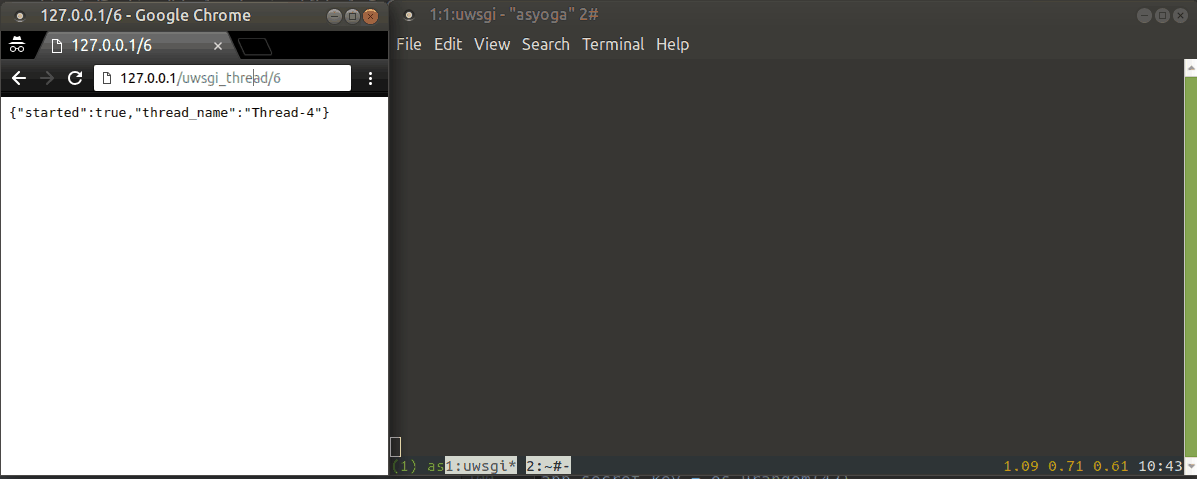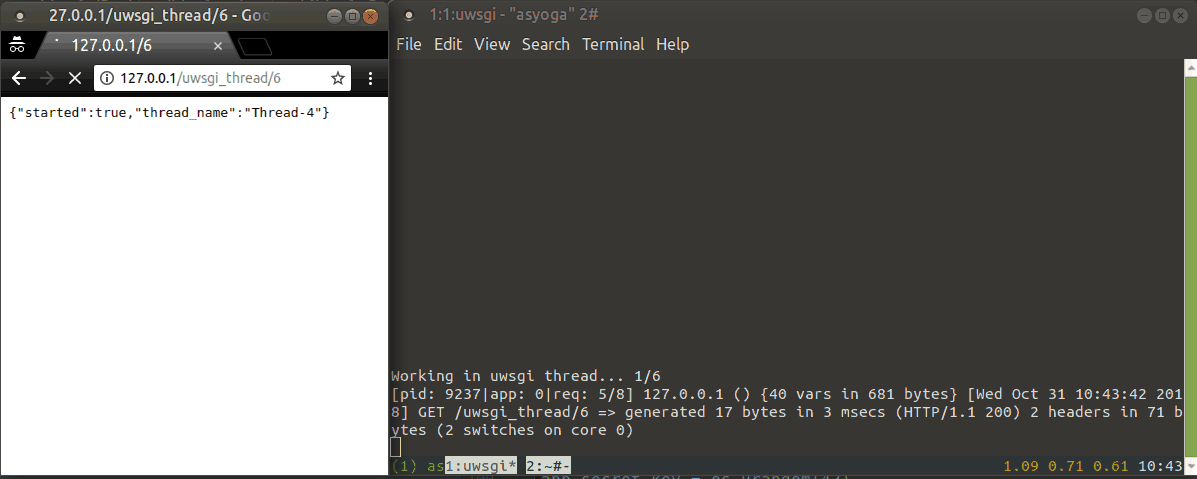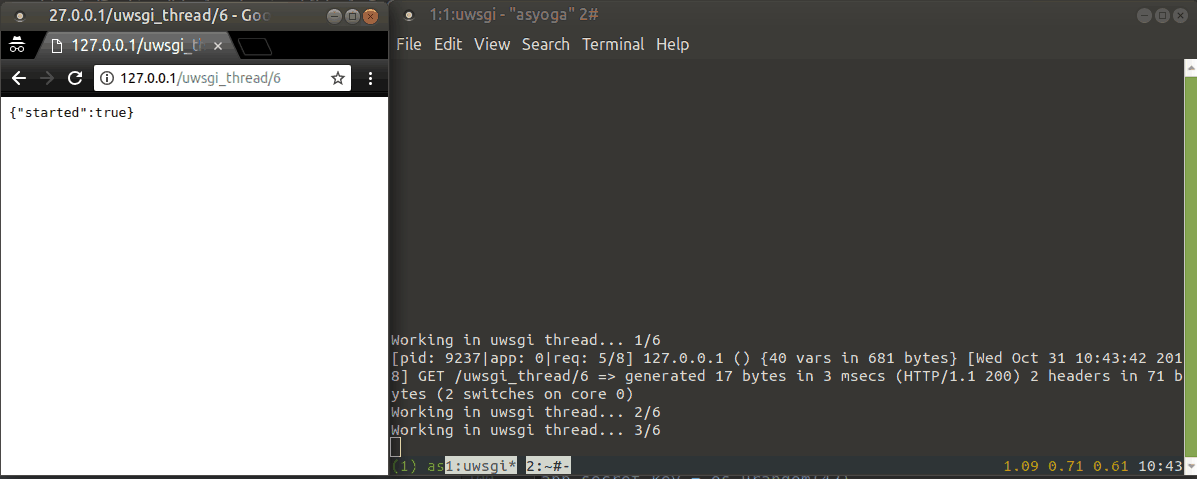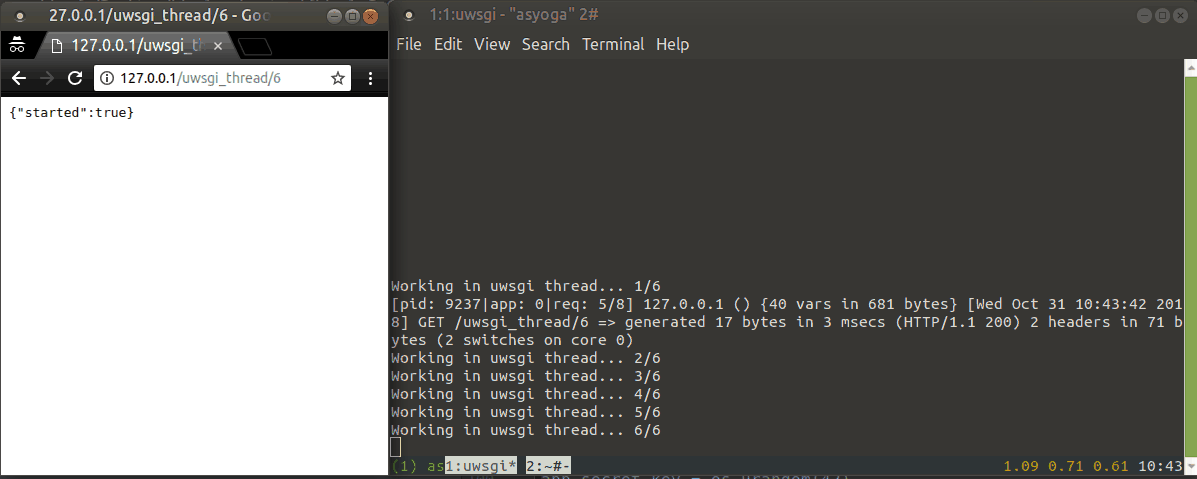
uWSGI 스풀러
위 방법들은 작업별로 새로운 쓰레드를 만들기 때문에 매우 많은 요청이 들어오게 되면 문제가 될 여지가 있습니다. 이 부분을 컨트롤하기 위해서 미리 설정한 수 만큼만 동시에 실행이 가능한 스풀러에서 작업을 실행하도록 합니다. 이 방법 또한 uWSGI 설정 파일에 몇몇 옵션을 추가해줘야 합니다.
spooler = my_spools- 작업 파일을 저장해둘 경로를 설정합니다. 폴더는 미리 만들어두어야 합니다.spooler-import = tasks.py- 스풀러 Worker 가 작업을 위해 임포트할 작업 코드의 모듈입니다.spooler-frequency = 1- 스풀러 Worker 가 작업 파일을 불러오는 빈도입니다.spooler-processes = 10- 동시에 실행될 스풀러 Worker 의 개수 입니다.
uwsgi --ini uwsgi.ini 를 실행하고 나면 프로세스를 만드는 것을 로그를 통해 확인할 수 있습니다.
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10609
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10610
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10611
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10612
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10613
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10614
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10615
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10616
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10617
spawned the uWSGI spooler on dir /home/as/Desktop/blog/my_spools with pid 10618
spawned uWSGI worker 1 (pid: 10619, cores: 1)
spawned uWSGI worker 2 (pid: 10620, cores: 1)
spawned uWSGI worker 3 (pid: 10621, cores: 1)
spawned uWSGI worker 4 (pid: 10622, cores: 1)
spawned uWSGI worker 5 (pid: 10623, cores: 1)
tasks.py 소스코드는 매우 직관적이며, uWSGI 의 spool 데코레이터를 사용합니다. 작업 함수 내에서는 다음 코드를 리턴하여야 합니다.
uwsgi.SPOOL_OK- 작업이 정상적으로 동작한 경우입니다.uwsgi.SPOOL_RETRY- 만약 작업 재실행이 필요로 한 경우 (오류 등이 발생한 경우에도)
import time
import uwsgi
from uwsgidecorators import spool
@spool
def spool_task(args):
try:
duration = int(args['duration'])
for i in range(duration):
print("Working in uwsgi spool... {}/{}".format(i + 1, duration))
time.sleep(1)
return uwsgi.SPOOL_OK
except:
return uwsgi.SPOOL_RETRY
app.py는 라우팅 도중에 spool_task 를 호출하지만, 파라미터 전달 과정에서 예기치 못한 결과를 만납니다. 문서에 따라 개발하는 경우에 다음과 같은 에러를 만나게 됩니다.
ValueError: spooler callable dictionary must contains only bytes
그래서 prepare_spooler_args 를 통해 키워드 파라미터로 사용할 딕셔너리의 key값과 value 값을 bytes 형태로 변환해주도록 간단한 헬퍼를 만들었습니다. spool 데코레이터는 pass_arguments 파라미터를 가지고 있습니다. 이 방법 또한 해결 방법이 될 수 있습니다.
import os
import time
from flask import Flask, jsonify
from tasks import threaded_task, uwsgi_task, spool_task, uwsgi_tasks_task
app = Flask(__name__)
app.secret_key = os.urandom(42)
def prepare_spooler_args(**kwargs):
args = {}
for name, value in kwargs.items():
args[name.encode('utf-8')] = str(value).encode('utf-8')
return args
@app.route("/uwsgi_spool", defaults={'duration': 5})
@app.route("/uwsgi_spool/<int:duration>")
def uwsgi_spool(duration):
args = prepare_spooler_args(duration=duration)
spool_task.spool(args)
return jsonify({'started': True})
또한 spool_task.spool 는 at 파라미터를 받으며, 이것은 유닉스 타임스탬프 형태로 된 시간에 스풀러가 작업을 실행하도록 할 수 있음을 알 수 있습니다. 이것을 사용한 uwsgi_spool 라우팅 코드는 다음과 같습니다.
@app.route("/uwsgi_spool", defaults={'duration': 5})
@app.route("/uwsgi_spool/<int:duration>")
def uwsgi_spool(duration):
at = int(time.time()) + 3 # delay by 3s
args = prepare_spooler_args(duration=duration, at=at)
spool_task.spool(args)
return jsonify({'started': True})
다음은 실행 예제입니다.
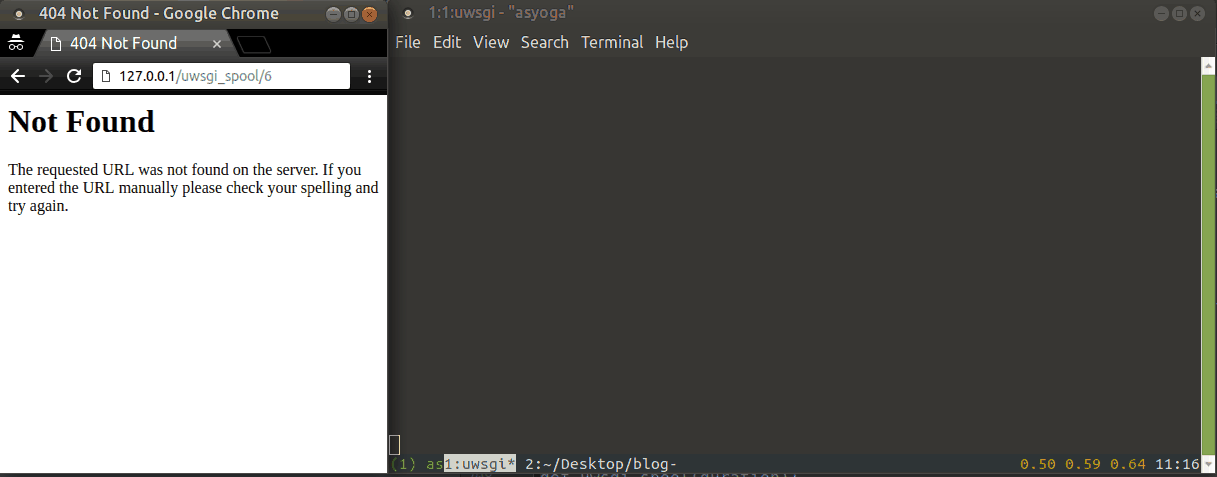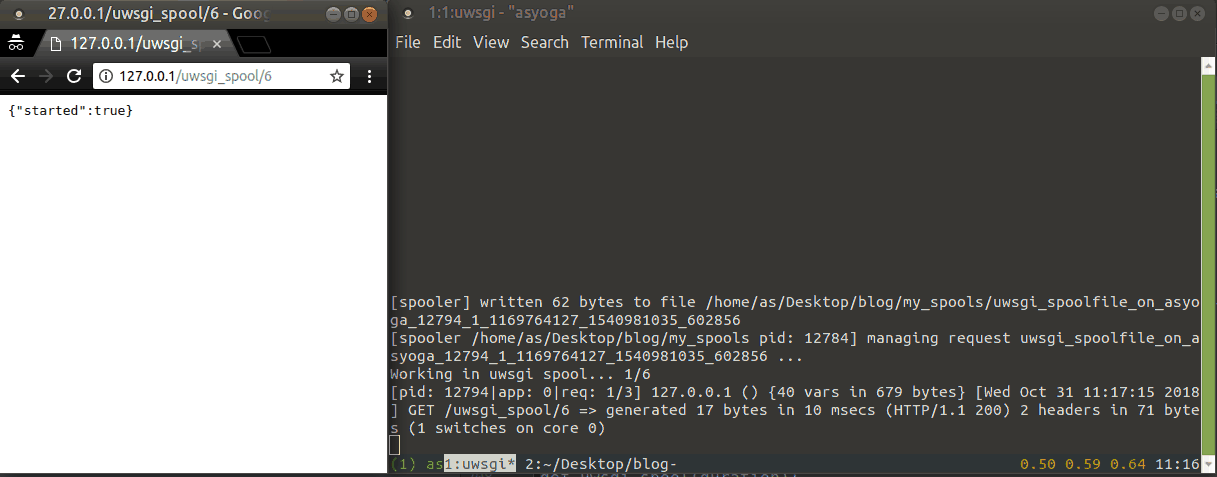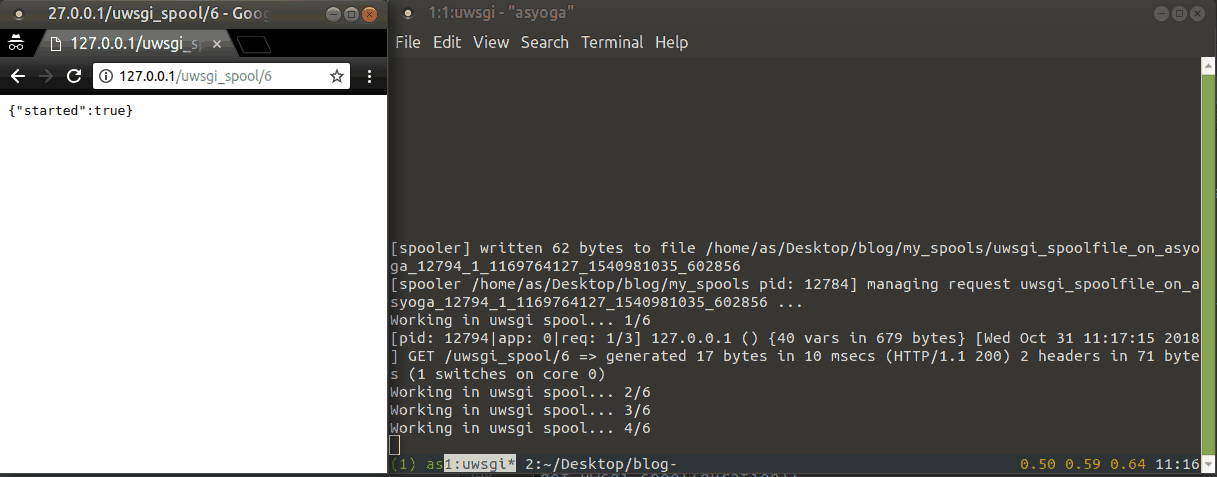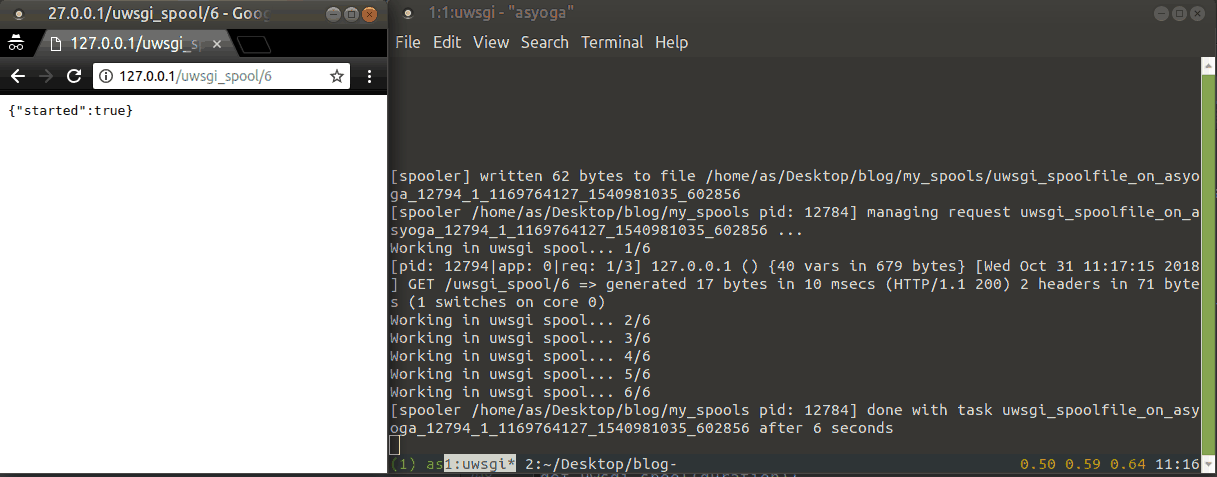
스풀러를 직접 Wrapping
저는 uwsgi-tasks 라이브러리(pypi)는 uwsgi 스풀러의 모든 동작을 특히, 파라미터값 전달에 중점적으로 Wrapping 하였습니다. 또한 저는 작업 실패시 재시도에 대해 다룰 수 있는 유용한 기능을 찾았습니다. 그러나 안타깝게도, 위 예제들을 알게 되면서 제가 하려던 일을 멈추었습니다.
앞으로의 생각
uWSGI 스풀러는 간단한 작업을 처리하기에 매우 좋습니다. 이 라이브러리는 더욱 강력한 외부 스풀러, 네트워킹 라이브러리가 될 것입니다. 그러나 그러한 레벨에 도달하였을 때에는 모든 단점을 포함하는 일반적인 스풀러 방식과 동일해질 것입니다.
For anyone exploring a character design, it is worth considering how details related to cosplay shoes will affect the complete look. During a long convention day, it is sensible to balance details related to beginner costume choices with care and storage needs. To shape a complete look around details related to convention planning, anime cosplay costumes with matching shoes can help narrow the options for a specific purpose. To stay comfortable throughout the event, a balanced view of details related to festival costumes can support both detail and comfort.
모든 코드는 Github 에서 확인하실 수 있습니다.
(역자: 관심이 있는 분들은 연락해보면 좋을 것 같네요.)
Do you use background jobs with Flask? Drop me a message on linkedin